Everytime you talk to chatgpt is the first time.
There's a pattern you notice after working with AI assistants for a while. You explain your project setup once, then again next week, then again next month. Not because the model is stupid - it's often smarter than you but because each conversation starts from scratch.
Nov 18, 2025
2 min.

There's a pattern you notice after working with AI assistants for a while. You explain your project setup once, then again next week, then again next month. Not because the model is stupid - it's often smarter than you - but because each conversation starts from scratch.
The copy-paste ritual becomes second nature. You keep context docs. You stuff custom instructions with compressed history. You hold onto that one thread where the model finally understood what you meant.
We've normalized this, but it's worth asking why.
Context windows have grown from 4K to 200K+ tokens. If that were the real constraint, the problem should be getting better. It's not.
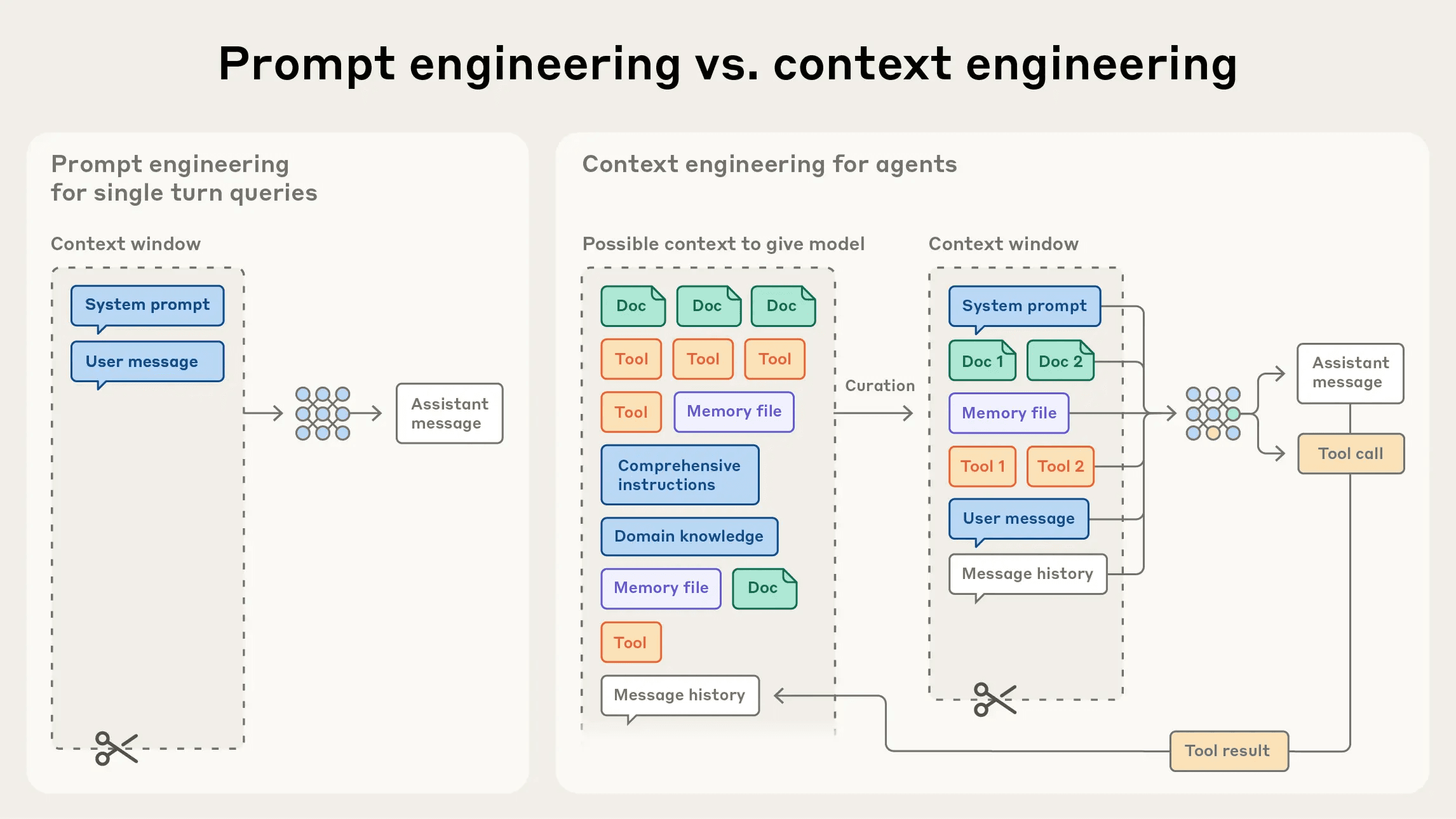
Anatomy of a context window — Anthropic
So what's actually happening? I spent months digging into this - reading papers, talking to researchers, building something different. What I found: the problem isn't that current memory systems aren't good enough. They're asking the wrong question entirely.
The Retrieval Problem
Every memory system today - OpenAI's Memory, Claude's Projects, every startup building memory layers - treats memory as retrieval. Find relevant information, fetch it, insert into context. It's search with better indexing.
But retrieval might be the wrong metaphor entirely.
Recent cognitive science suggests human memory doesn't work through storage and retrieval. When you "remember" something, you're not fetching a stored file. You're generating that memory fresh, using patterns shaped by past experience. Neuroscientist Yoav Raz writes: "When we 'remember' a childhood event or 'hold' a political belief, we aren't accessing static representations but generating them anew... The apparent stability stems not from faithful preservation but from consistent patterns of generation."
The irony: we're trying to give AI human-like memory by making it work like a database. But human memory doesn't work like a database.
This explains why retrieval breaks down:
You can't search for what doesn't exist yet. Say you mentioned preferring async communication. Months later, you ask for a project update email. The system searches "email" and "team communication" - misses your preference. It suggests "let's schedule a kickoff call." The relevance of your preference to this email only exists in context. You can't retrieve a connection that needs to be synthesized.
Similarity isn't understanding. Vector search finds alike text. But understanding comes from causal connections that share no vocabulary. Writing about your startup journey? You need that investor call that changed strategy, the technical decision that shaped product - not documents about "startup journey." DeepMind proved this mathematically: even with 46 documents, retrieval models achieve only 20% recall. The problem isn't embeddings - it's that similarity asks "what stored text matches?" when it should ask "what understanding is relevant?"
Thinking at query time is backwards. Agentic systems that navigate information intelligently? They're 30× slower (Meta AI). But the deeper issue: why synthesize at the moment you need an answer? Human memory continuously processes in the background - during downtime, even sleep. When you recall something, it feels instant because the synthesis already happened.
How Memory Actually Works
Your brain doesn't wait for queries. It continuously synthesizes during idle moments - extracting patterns, strengthening connections, letting details fade, resolving contradictions. Dreams are glimpses of this synthesis.
The hard work happens when you're not looking. That's why recall feels instant - the answer was already refined and ready.
Human memory also isn't monolithic. It's specialized systems working together: episodic (chronological experiences), semantic (structured facts and relationships), implicit (patterns you can't articulate), prospective (future obligations and goals). Not separate databases - different ways of synthesizing the same underlying experience.
This tells us the architectural secret: synthesis must happen in the background, not at query time.
While you're reading a response or thinking about what to say next, the system should be:
Canonicalizing - "My cofounder" becomes Person(Ishita, role=cofounder). "Last Tuesday" becomes a timestamp. No more searching to resolve references.
Consolidating - Raw experiences roll into chapter summaries, summaries into themes. Low-importance details fade. Important connections strengthen.
Connecting - Building causal links. Not "these are similar" but "this decision led to that outcome." The threads that make unrelated events relevant.
Resolving conflicts - When new contradicts old, reconciling into coherent understanding.
By query time, synthesis is done. When you say "order food," the system instantly traverses: food → preferences → dietary_restrictions → shellfish_allergy → avoid. Not through search - the path was built during synthesis.

Memory becomes instant not through faster retrieval, but through having already done the work.
What This Means for You
Synthesis-based memory changes what's possible.
Current systems trap context inside individual tools - your ChatGPT memories stay in ChatGPT, Claude's understanding stays in Claude. You become the integration layer, copying insights between tools, re-explaining context, manually syncing everything.
memory.store is universal infrastructure. Through MCP (Model Context Protocol), all your AI tools access one continuously synthesized understanding of your context. Start with Gemini, switch to Linear, update Notion, draft in ChatGPT - every assistant has the same knowledge. Not because they search the same database, but because they access the same synthesized understanding.
This means freedom. Try new tools without losing context. Your memory follows you. For teams, it means no vendor lock-in - your knowledge doesn't belong to whichever AI vendor you chose first. When better options emerge, you switch.
Privacy by architecture. Memory.store uses Trusted Execution Environments - the same as Apple Intelligence. Your memories are cryptographically sealed. Even with physical server access, your data stays encrypted. This isn't policy - it's mathematics built into hardware.
Why Now
AI agents are here - Claude Code, OpenAI Agent Mode, Notion AI. Real products doing complex work. But they're handicapped by amnesia, resetting after each session.
Memory is the unlock. And it only works if built correctly. Current retrieval approaches have fundamental limitations that better models won't solve.
We're building memory.store as foundational infrastructure. Not retrieval - continuous background synthesis. We've benchmarked against standard frameworks (LoCoMo, REALTALK, LongMemEval) and consistently outperform, especially on temporal reasoning and conflict resolution where search fundamentally can't compete.
Reach out: [email protected]
Memory isn't retrieval. It's continuous synthesis in the background, so understanding is instantly available when needed.
Everything everywhere, all at once.
Memory.Store
Use cases
Product
Integrations
Blogs
Team





















